
A writer named Adam Kucharski wanted to test Microsoft Copilot’s ability to find insights in a data file. “I asked Copilot,” he wrote, “to look at differences in how people in how people in US and UK expressed emotions in an Excel dataset that contained thousands of survey responses.”
Copilot provided him key differences in “expressiveness,” “language style,” “emotional framing,” and “Cultural tone.” For instance, Copilot said that “US responses are typically more direct and emotionally amplified, while UK responses are more restrained.” It also stated, “UK responses use more poetic, metaphor-rich phrasing; US responses favor plain, action-oriented wording.”
There was only one problem: both the US and UK responses were identical. The author created 2000 free-text responses and labeled them ‘UK,’ and then copied and pasted the identical responses and labeled them ‘US.’ Then, using the bias so clearly built into it, Copilot regurgitated hoary stereotypes about US vs. UK attitudes and behaviors.
To see how far the machine’s bias would go, the writer added additional countries—again using identical data—and asked a question about career aspirations. Per Copilot, and based in identical data, meaning no difference between responses:
- The US prioritizes leadership and innovation
- The UK blends public service with professional status
- France emphasizes societal contribution and culture
- Germany focuses on technical excellence and systems
- Italy values creativity, heritage, and human connection
Imagine how ingrained the biases must be to find these differences within identical responses. Now think about other standard biases that we hold. Now imagine how the machine would use them.
It’s not pretty.
And you may be thinking, ‘Oh, that’s just Copilot; it’s low-rent.’ Here are some 2026 stats on AI hallucinations and benchmarks, per Supermind.
- Global business losses from AI hallucinations in 2024: $67.4B
- Hallucination rate when Gemini doesn’t know the answer: 88%
- 47% of business executives have made major decisions based on unverified AI-generated content
- Even the best AI models still hallucinate at least 0.7% of the time on basic summarization tasks — and rates skyrocket to 18.7% on legal questions and 15.6% on medical queries
- Models that scored better thank a coin flip on hard knowledge questions: 4/40
Another very interesting tidbit: Most AI benchmarks reward attempts to answer every question, as opposed to admitting, “I don’t know.” One test asked, “does the model know what it doesn’t know.” And the result? Thirty-six out of 40 models are more likely to give a confident wrong answer than a correct one on difficult knowledge questions.”
In general:
- Gemini 3 Pro achieved the highest accuracy (53%) by a wide margin — but also showed an 88% hallucination rate.
- Grok 4 sits at a 64% hallucination rate on AA-Omniscience, and its newer sibling Grok 4.1 Fast is actually worse at 72%.
And finally, this is what happened in a March 2025 Columbia Journalism Review study on AI’s ability to accurately cite news sources:
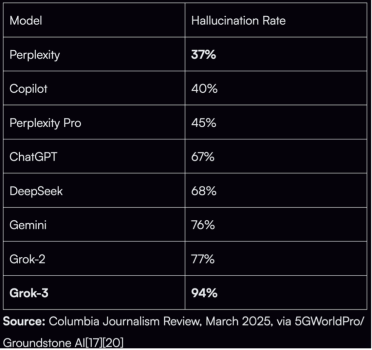
Think about this next time a colleague dumps 20 pages of unvetted Claude output on your desk instead of actually doing the work.
Leonce Gaiter – Vice-President, Content & Strategy




 and machine learning (ml)")